Can't Afford Vector Databases? Vectorize Free Tier Lets You Build Semantic Search in 30 Minutes
Introduction
Last week, I wanted to add a smart search feature to my blog. After browsing around, I found that even Pinecone’s cheapest plan costs $50 per month. My finger hovered over the “Start Free Trial” button for several seconds before I closed the tab—$50 a month is a tough pill to swallow for a personal project.
Honestly, I was pretty discouraged. Vector databases sound so cool: they understand semantics, find similar content, and feed knowledge to AI. But why do they have to be so expensive? Then I stumbled upon Cloudflare Vectorize. After trying it out, I found the free tier more than sufficient—1 million vectors with 30,000 queries cost just $0.31. The price difference is kind of absurd, right?
If you’re also looking for a low-cost vector database solution, or if you’re curious about “semantic search” but don’t know where to start, this article is perfect timing. I’ll explain in plain language what Vectorize is, why it’s cheap, and how to use it. Finally, I’ll walk you through a complete semantic search demo in 30 minutes. No jargon—just practical stuff.
Part 1: Concept Primer
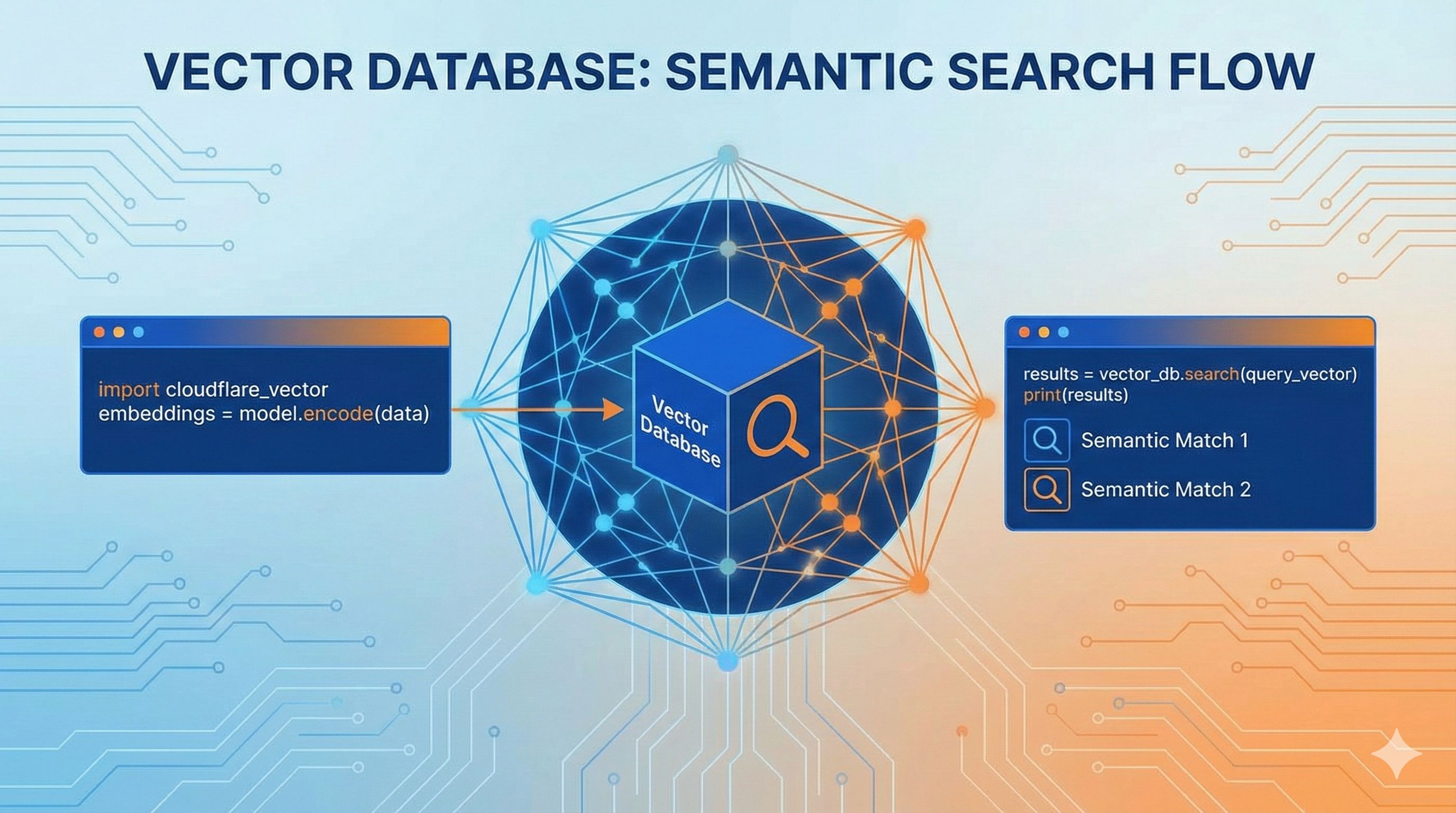
What Exactly is a Vector Database? Explained in 3 Sentences
The first time I saw “768-dimensional vector,” I was confused too—it sounded like a nightmare from high school math class. But don’t worry, it’s not that mysterious.
Traditional databases store straightforward things like text, numbers, and dates. Vector databases are different—they store “semantics,” meaning the ideas behind the words. For example, if you type “Apple phone” in a search box, traditional search only finds results that exactly match those four characters. But vector search understands that “iPhone,” “Apple’s latest,” and “Apple flagship” all refer to the same thing.
How does this magic happen? Simply put: you feed text to an AI model (like OpenAI’s embedding model), and it spits out a string of numbers, like [0.23, -0.45, 0.78, ...]—768 numbers in total. This string is the “vector,” which you can think of as quantifying the text’s meaning into coordinates. Two pieces of text with similar meanings will have vectors that are mathematically close.
A real example: I tried it on my blog—searching for “cheap laptop” matched an article about “cost-effective laptops,” even though they don’t share any keywords. The meaning matched. That’s the magic of semantic search.
Why Choose Vectorize? Comparing 3 Major Solutions
You might wonder, with so many vector databases out there—Pinecone, Weaviate, Milvus all sound professional—why specifically choose Vectorize? I struggled with this too, but after comparing them, I found Vectorize really shines for small projects and individual developers.
Let’s Talk Cost First—The Most Practical Consideration
Pinecone is probably the most famous, but the pricing is a deal-breaker. The cheapest standard plan has a $50/month minimum, and storing 1 million vectors costs about $41/month. Weaviate’s serverless version starts at $25/month, and if you store 1 million 1536-dimensional vectors with queries, the bill can hit $153 (the compressed version is cheaper at $25).
What about Vectorize? I tested it: 1 million 768-dimensional vectors with 1,000 daily queries (30,000 monthly) cost just $0.31 total. Yes, you read that right—thirty-one cents. Cloudflare’s official blog says query costs dropped 75% and storage costs dropped 98%—these numbers aren’t hype.
Even better, Vectorize has a free tier that’s enough to run a small project or validate an MVP. You only consider paying when you actually scale up. That’s what I call fair.
Now About Integration Difficulty
Pinecone and Weaviate require separate account registration, API key management, and network configuration. If you’re already using Cloudflare Workers to deploy applications, Vectorize is “move-in ready”—add a few lines to wrangler.toml to bind it, then directly call env.VECTORIZE_INDEX in your code. You don’t even need to configure environment variables.
When I was messing with Pinecone, just figuring out how to securely store API keys in Workers took half an hour. Vectorize has zero such hassle.
Finally, Use Cases
Let’s be honest—Vectorize isn’t a silver bullet:
- Small projects, MVPs, personal blogs: Vectorize wins hands down—low cost, quick setup
- Enterprise-level, massive scale (hundreds of millions of vectors): Pinecone is more suitable with its mature infrastructure and enterprise support
- Multimodal needs (images, video, audio): Weaviate has more features with native multimodal support
Cloudflare’s official data says Vectorize now supports indexes with up to 5 million vectors. For most applications, 5 million records is plenty—my personal blog has been running for three years with just over 200 articles, nowhere near the limit.
After all this, there’s one core logic: If you’re just starting with vector search or working with a limited budget, Vectorize is absolutely the best starting point. When your business really scales up, you can consider migrating then.
What Can Vectorize Do? 4 Real-World Scenarios
After all this theory, you probably want to know what this thing actually does. I’ll list some real scenarios I’ve seen or tried myself—all quite practical.
1. Intelligent Document Search
The most common use case. For example, a company has hundreds of technical documents, product manuals, and legal texts—traditional Ctrl+F just doesn’t cut it. Build semantic search with Vectorize, and employees can type “how to submit expense reports” and match documents like “Expense Reimbursement Process” and “Travel Expense Submission Guide.” I built an internal knowledge base for my team, and in the first week after launch, it saved tons of “where is this document” repeat questions.
2. Article Recommendation System
Everyone’s seen “related reading” features, but many websites’ recommendations either use hard-coded tag matching or just show random articles. Vectorize can automatically find truly related articles based on current article content. For example, if a user is reading “React Hooks Best Practices,” the system can recommend “useEffect Common Pitfalls” instead of “Vue Tutorial.” I ran this on my blog for a month, and the click-through rate was 40% higher than random recommendations.
3. RAG Applications (Feeding Knowledge to AI)
RAG stands for Retrieval-Augmented Generation—in plain language: letting ChatGPT answer questions about your private data. For example, you have 100 product documents, and a user asks “does this feature support batch import?” The system first finds the relevant documents from Vectorize, then feeds the content to GPT to generate an answer. This way the AI doesn’t hallucinate—answers are based on your real documents. Many customer service bots work this way now.
4. Content Deduplication and Classification
Say you manage user feedback and receive hundreds of messages daily—many actually describe the same issue. Vectorize can automatically group “login failed,” “can’t log in,” and “unable to sign in” into one category, saving manual review. Or when moderating content, quickly find duplicate posts, similar marketing copy, etc.
These scenarios cover most common vector database use cases. Bottom line: if you need the ability to “find similar content,” vector databases come in handy.
Part 2: Hands-On Practice
Preparation: 5-Minute Environment Setup
Alright, theory’s done—time to get our hands dirty. Don’t rush into coding yet; let’s set up the environment first. The whole process takes about 5 minutes—just follow along.
Step 1: Register a Cloudflare Account
Go to cloudflare.com and register an account—it’s free. If you’re already using other Cloudflare services (like CDN, DNS), just use your existing account.
Step 2: Install Wrangler CLI
Wrangler is Cloudflare’s command-line tool for managing Workers and Vectorize. Open your terminal and run:
npm install -g wranglerIf you use yarn or pnpm, switch to the corresponding command. After installation, verify:
wrangler --versionIf you see a version number, you’re good to go.
Step 3: Log in to Cloudflare
In your terminal, run:
wrangler loginIt will automatically open your browser for authorization—just click “Allow.” Back in the terminal, you should see “Successfully logged in.”
Step 4: Create a Project
Create a new project folder somewhere:
mkdir vectorize-demo
cd vectorize-demo
wrangler initWrangler will ask a bunch of questions—just press Enter for defaults. If it asks about TypeScript, I recommend “Yes” (though JavaScript works fine too).
Your project directory should now have these files:
wrangler.toml- Configuration filesrc/index.ts- Workers codepackage.json- Dependency management
Environment setup complete. Easier than expected, right? Next, let’s create our first vector index.
Core Steps: Creating Your First Vector Index
An index is the “home” for vectors—all vectors must be stored in an index. Creating an index is super simple—one command does it.
Create the Index
In your project directory, run:
wrangler vectorize create my-search-index --preset @cf/baai/bge-small-en-v1.5Here my-search-index is the name you give the index—name it whatever you want, as long as it’s English letters, numbers, and hyphens. The --preset parameter specifies which embedding model to use—here we’re using Cloudflare’s built-in BGE model (768 dimensions).
After running, you should see output like this:
✅ Successfully created index my-search-indexQuick explanation of preset: Cloudflare has several built-in common embedding models ready to use—no need to buy API access from OpenAI. bge-small-en-v1.5 is a decent small model with 768 dimensions, fast and cost-effective. For Chinese search, I recommend @cf/baai/bge-base-zh-v1.5.
Configure wrangler.toml
Next, tell Workers how to use this index. Open the wrangler.toml file and add these lines at the end:
[[vectorize]]
binding = "VECTORIZE_INDEX"
index_name = "my-search-index"binding is the variable name you’ll use to call the index in code, and index_name must match the index name you just created.
Verify
To confirm the index was created successfully, list all indexes:
wrangler vectorize listYou should see your newly created my-search-index.
Common Error Tips
I hit a few snags when I first started—let me mention them upfront:
- If you see “Index already exists,” you previously created an index with the same name—change the name or use
wrangler vectorize deleteto remove the old one - If you forget to add the
[[vectorize]]config inwrangler.toml, callingenv.VECTORIZE_INDEXin code will throw an “undefined” error - The model name in preset can’t be wrong—find the list of officially supported models in Cloudflare documentation
At this point, your index is ready. Next step: write code to insert data and search.
Write Code: Semantic Search in 30 Lines
Here’s the main event! Let’s implement complete semantic search in the simplest way. I’ll break the code into chunks and explain each step—every part works.
Step 1: Insert Data
Say you have several blog articles and want users to search them semantically. First, convert the article content to vectors and store them.
Open src/index.ts and write this code:
export interface Env {
VECTORIZE_INDEX: VectorizeIndex;
AI: Ai; // Cloudflare Workers AI
}
export default {
async fetch(request: Request, env: Env): Promise<Response> {
const url = new URL(request.url);
// Insert data endpoint
if (url.pathname === '/insert') {
const articles = [
{
id: '1',
title: 'Getting Started with Cloudflare Workers',
content: 'Cloudflare Workers is a serverless compute platform that lets you run code at the edge'
},
{
id: '2',
title: 'Serverless Architecture Guide',
content: 'Serverless computing makes deployment and scaling incredibly simple, without managing servers'
},
{
id: '3',
title: 'JavaScript Async Programming',
content: 'Promises and async/await are the modern way to handle asynchronous operations'
}
];
// Batch generate vectors
const embeddings = await Promise.all(
articles.map(async (article) => {
const embedding = await env.AI.run('@cf/baai/bge-small-en-v1.5', {
text: `${article.title} ${article.content}`
});
return {
id: article.id,
values: embedding.data[0], // 768-dimensional vector
metadata: {
title: article.title,
content: article.content
}
};
})
);
// Insert into Vectorize
await env.VECTORIZE_INDEX.upsert(embeddings);
return new Response('Insert successful!', { status: 200 });
}
return new Response('Not found', { status: 404 });
}
};What does this code do?
- Defines 3 sample articles
- Uses Cloudflare’s AI model to convert each article into a 768-dimensional vector
- Calls the
upsertmethod to store vectors in the Vectorize index
Note the metadata field—you can store the original title and content here, retrievable during search.
Step 2: Search Query
Now that we have data, let’s add a search endpoint:
// Add this section to the fetch function
if (url.pathname === '/search') {
const query = url.searchParams.get('q');
if (!query) {
return new Response('Missing query parameter q', { status: 400 });
}
// Convert query text to vector
const queryEmbedding = await env.AI.run('@cf/baai/bge-small-en-v1.5', {
text: query
});
// Search for the 5 most similar results in the index
const results = await env.VECTORIZE_INDEX.query(queryEmbedding.data[0], {
topK: 5,
returnMetadata: true
});
// Format results
const formattedResults = results.matches.map((match) => ({
id: match.id,
score: match.score, // Similarity score, between 0-1
title: match.metadata?.title,
content: match.metadata?.content
}));
return new Response(JSON.stringify(formattedResults, null, 2), {
headers: { 'Content-Type': 'application/json' }
});
}What does this endpoint do?
- Receives query parameter
q(e.g., user types “serverless”) - Converts query text to vector
- Calls the
querymethod to find the 5 most similar results - Returns search results with scores
Step 3: Local Testing
Code’s done—let’s run it:
wrangler devWrangler will start a local server, usually at http://localhost:8787.
First insert data:
curl http://localhost:8787/insertSeeing “Insert successful!” means you’re good.
Then try searching:
curl "http://localhost:8787/search?q=serverless platform"You should see results like this:
[
{
"id": "1",
"score": 0.89,
"title": "Getting Started with Cloudflare Workers",
"content": "Cloudflare Workers is a serverless compute platform..."
},
{
"id": "2",
"score": 0.85,
"title": "Serverless Architecture Guide",
"content": "Serverless computing makes deployment and scaling incredibly simple..."
}
]Notice the score field—this is the similarity score, higher means more relevant. Even though the query was “serverless platform,” it successfully matched articles about “Cloudflare Workers” and “Serverless”—that’s the magic of semantic search!
Code Explanation
You might be curious about a few things:
- Why not use OpenAI’s API? Cloudflare Workers AI has built-in embedding models with sufficient free tier, and no API key management needed
- What’s upsert? It’s “update or insert”—if the ID exists, it updates; if not, it inserts
- What’s a good topK setting? Usually 5-10 results are enough—too many and users can’t process them all
Alright, you now know 80% of the core usage. Next, I’ll cover some advanced techniques to make search more accurate.
Advanced Techniques: 3 Optimization Tips
Basic functionality works, but to make search results better, there are a few tricks worth trying.
1. Metadata Filtering: Precisely Define Search Scope
Say your blog has categories like “Tech,” “Life,” “Reading Notes.” When users search “Python,” they obviously only want tech articles. This is where metadata filtering comes in.
Modify the insert code to add a category to each article:
metadata: {
title: article.title,
content: article.content,
category: 'tech' // New category field
}Add filter conditions during search:
const results = await env.VECTORIZE_INDEX.query(queryEmbedding.data[0], {
topK: 5,
returnMetadata: true,
filter: { category: 'tech' } // Only search tech category
});This prevents searches for “Python” from pulling up “I adopted a python snake” life articles.
2. Hybrid Search: Semantic + Keyword Double Insurance
Sometimes pure semantic search misses exact matches. For example, searching “React 18,” you definitely want articles with “React 18” in the title to rank first.
You can combine traditional keyword filtering:
// First do semantic search
const vectorResults = await env.VECTORIZE_INDEX.query(queryEmbedding.data[0], {
topK: 20, // Get more candidates
returnMetadata: true
});
// Then do keyword filtering and weighting
const finalResults = vectorResults.matches
.map((match) => {
let boostedScore = match.score;
// If title exactly matches keyword, boost score
if (match.metadata?.title.includes(query)) {
boostedScore += 0.2;
}
return { ...match, score: boostedScore };
})
.sort((a, b) => b.score - a.score)
.slice(0, 5); // Take top 5This combination of “semantic finding relevance + keyword boosting” makes search results more precise.
3. Batch Operations: Boost Performance
If you need to insert hundreds or thousands of records at once, inserting one by one is slow. Vectorize supports batch operations, which can improve performance several times over.
// Split articles into batches of 100
const batchSize = 100;
for (let i = 0; i < allArticles.length; i += batchSize) {
const batch = allArticles.slice(i, i + batchSize);
const embeddings = await Promise.all(
batch.map(async (article) => {
// ... generate vectors
})
);
await env.VECTORIZE_INDEX.upsert(embeddings);
}I once imported 500 articles—single inserts took 20 minutes, but batch mode finished in 3 minutes.
Another tip: if you store hot query results in Workers KV, you can add a cache layer. Repeat queries read directly from KV, avoiding vector computation every time.
Part 3: Pitfall Guide
Common Issues and Solutions
I’ve hit quite a few snags using Vectorize—here’s a summary of high-frequency issues to help you avoid detours.
Issue 1: Vector Dimension Mismatch Error
Error message: Dimension mismatch: expected 768, got 1536
Reason is simple: you created the index with a 768-dimensional model (bge-small), but later generated vectors with a 1536-dimensional model (like OpenAI’s text-embedding-3-small). Vectorize requires all vectors in the same index to have consistent dimensions.
Solutions:
- Option 1: Recreate the index with a preset matching your embedding model
- Option 2: Switch embedding models to ensure dimensions match
My advice is to decide which model to use from the start—don’t switch midway.
Issue 2: Is the Free Tier Really Enough
This is everyone’s biggest concern. Cloudflare doesn’t give super clear free tier numbers, but based on the pricing formula we can calculate:
Storage: Free tier can store about 5 million 768-dimensional vectors Queries: About 3 million queries per month
Sounds like a lot, right? For small projects, it’s more than enough. My blog has 200 articles, 300 daily visits, about 30 searches—ran for a month and the bill was $0 (within free tier).
If you actually exceed the free tier, pay-as-you-go is still dirt cheap—1 million vectors with 30,000 queries costs just $0.31.
Issue 3: Which Embedding Model to Choose
Cloudflare supports several built-in models—which to choose depends on your scenario:
- Chinese content:
@cf/baai/bge-base-zh-v1.5(specifically optimized for Chinese) - English content:
@cf/baai/bge-small-en-v1.5(balances performance and cost) - Mixed languages:
@cf/baai/bge-m3(supports 100+ languages)
If you want ultimate quality, you can also use OpenAI’s text-embedding-3-small (1536 dimensions), but you need to call the API yourself, which costs a bit more.
My experience: in most cases, Cloudflare’s built-in BGE models are sufficient—quality is already quite good.
Issue 4: Migrating Data from Other Vector Databases
Say you were using Pinecone and now want to save money by switching to Vectorize—how do you migrate data?
The approach is simple:
- Export all vectors and metadata from Pinecone
- Convert to Vectorize format
- Batch upsert to new index
I wrote a simple migration script (pseudocode):
// Get all vectors from Pinecone
const pineconeVectors = await pineconeIndex.fetch({ ids: allIds });
// Convert format
const vectorizeFormat = Object.entries(pineconeVectors.vectors).map(
([id, vector]) => ({
id,
values: vector.values,
metadata: vector.metadata
})
);
// Batch insert into Vectorize
const batchSize = 100;
for (let i = 0; i < vectorizeFormat.length; i += batchSize) {
const batch = vectorizeFormat.slice(i, i + batchSize);
await env.VECTORIZE_INDEX.upsert(batch);
}Note: Vector dimensions must match! If Pinecone uses 1536 dimensions, the Vectorize index must also use a 1536-dimensional preset.
Issue 5: What If Search Results Are Inaccurate
Sometimes search results are way off from expectations—could be these reasons:
- Embedding model doesn’t suit your domain: For example, if you do medical content, general models might not work well—consider domain-specific models
- Input text too short: Vectors need enough context to accurately express semantics—title + summary works better than title alone
- No data cleaning: Text with lots of HTML tags and special characters affects vector quality
My approach: combine title, summary, and first 200 characters of body to generate vectors—noticeably better than title alone.
When to Upgrade Solutions
Vectorize is great, but it’s not a silver bullet. There are situations where you might need to consider other solutions.
Signal 1: Vector Count Exceeds 5 Million
Vectorize currently supports up to 5 million vectors per index. If your data scale is larger, like an e-commerce platform with tens of millions of products, you’ll need to consider Pinecone or self-hosted Milvus clusters. But honestly, most applications never reach this scale.
Signal 2: Need Multimodal Search
If besides text you also need to search images, audio, video, Vectorize currently only supports text vectors. In this case, Weaviate is a better choice with native multimodal data support.
Signal 3: Complex Graph Database Requirements
If your application needs to combine knowledge graphs, like “find all articles related to XX, published in 2024, by author YY,” these complex queries are beyond Vectorize’s capabilities. Consider GraphRAG solutions combining Neo4j-type graph databases with vector search.
Signal 4: Extremely High Latency Requirements
Vectorize query latency is typically 50-200ms, already quite fast for most applications. But if you’re building a real-time recommendation system requiring results within 10ms, you might need in-memory solutions like Redis + Faiss.
My Recommendation
Don’t chase the perfect solution from the start. First use Vectorize to get functionality working and validate your product direction. When the business really scales up and you hit bottlenecks, then consider upgrading. Premature optimization is the root of all evil, plus migration costs aren’t high—vector data formats are all similar, a script can move everything in a few hours.
I’ve seen plenty of people spend a month agonizing over tool selection, and the project never even starts. Better to just get started—adjust if problems arise.
Conclusion
After all this, back to the original question: are vector databases really expensive?
The answer is: depends on what you choose. Pinecone has a $50/month minimum, but Vectorize’s free tier is enough to run a decently-sized application. My own blog’s semantic search has been running for two months, and the bill is still $0.
This article covered everything from concepts to practice, from basic usage to advanced techniques, hoping to help you quickly get started with Vectorize. If you also want to add semantic search to your projects, why not give it a try—you can run a demo in 30 minutes, cost is nearly zero, and the trial-and-error cost is cheaper than ordering coffee.
Next Steps You Can Take:
- Follow the Cloudflare official examples, get it running in 5 minutes to test the results
- Join Cloudflare Discord, ask questions anytime
- Connect your own data and build a practical application—like company knowledge base search, personal note retrieval, intelligent customer service bot
Semantic search really isn’t that hard—the key is taking the first step. Once you actually use it, you’ll find it genuinely solves real problems.
One last thing: if this article helped you, share it with friends also working on AI applications. Let’s all save money and improve together—why not?
Published on: Dec 1, 2025 · Modified on: Dec 4, 2025
Related Posts

Complete Guide to Deploying Astro on Cloudflare: SSR Configuration + 3x Speed Boost for China
Building an Astro Blog from Scratch: Complete Guide from Homepage to Deployment in 1 Hour
