AI服务商切换太麻烦?一个AI Gateway搞定监控、缓存和故障转移(成本降40%)
引言
凌晨两点,你被电话吵醒,客户说AI功能挂了。打开监控一看,OpenAI又双叒限流了。你赶紧打开代码,把所有openai.chat.completions.create改成Claude的API,结果发现Claude的请求格式完全不一样,messages要改成anthropic.messages.create,参数结构也不对…改到三点半终于上线,累得要死。 第二天早上,老板发来账单截图:“这个月AI费用怎么从500美元飙到8000美元了?!”你一脸懵,根本不知道钱都花哪了,哪个团队用得最多,有多少是重复请求…完全一团乱麻。 说实话,这种痛苦经历,只要做过AI应用的人都懂。多个AI服务商切来切去太麻烦,成本失控心里慌,服务挂了业务就炸,想想都头疼。 其实,你只需要一个AI Gateway,就能彻底解决这些问题。改一行代码,OpenAI、Claude、Gemini随便切;自动故障转移,主模型挂了秒切备用;智能缓存加监控,成本直接降40%。今天这篇文章,我手把手教你10分钟搭建自己的AI Gateway,从此告别半夜改代码的噩梦。
为什么需要AI Gateway?三个真实痛点
痛点1:多服务商切换是噩梦
你可能有这种经历:项目开始用的OpenAI GPT-4,后来发现Anthropic的Claude在某些任务上效果更好,于是想切过去试试。打开代码一看,整个人都不好了。 OpenAI是这样调用的:
const openai = new OpenAI({apiKey: 'sk-xxx'});
const response = await openai.chat.completions.create({
model: "gpt-4",
messages: [{role: "user", content: "Hello"}]
});Claude是这样的:
const anthropic = new Anthropic({apiKey: 'sk-ant-xxx'});
const response = await anthropic.messages.create({
model: "claude-3-5-sonnet-20241022",
max_tokens: 1024,
messages: [{role: "user", content: "Hello"}]
});看到没?连基础结构都不一样,还有一堆参数差异。如果你的代码里有几十个地方调用AI,改起来能崩溃。更惨的是,Google Gemini、Cohere、Azure OpenAI…每家API格式都不一样,这哪顶得住啊! 数据不会骗人:调研显示70%的AI应用都在用2个以上的模型服务商。为啥?不同模型擅长不同任务,GPT-4贵但效果好,Claude便宜点适合批量,Gemini免费额度高适合测试…你总得切换吧?但切换成本高到让人怀疑人生。
痛点2:成本黑洞无法控制
说个真事:我朋友公司做了个AI客服,开始每月500美元,挺正常。突然某个月账单8000美元,老板直接炸了。查了半天才发现,是有个开发测试时忘了删日志,每次请求都调了两遍API,而且缓存没开,同样的问题重复问了无数次。 这就是没有统一监控的痛。你根本不知道:
- 每天花了多少钱? 等账单出来已经晚了
- 哪个团队用得最猛? 产品那边在疯狂测试,你还被蒙在鼓里
- 哪些请求最贵? GPT-4的长文本生成是大头,但你不知道
- 有多少浪费? 40%的重复请求在烧钱,你看不见 某机构报告显示,企业AI支出同比增长300%,但其中有40%是重复请求造成的浪费。这钱花得多冤啊!
痛点3:单点故障随时爆炸
2024年OpenAI至少宕机了6次,平均每次2小时。如果你的服务完全依赖OpenAI,那就是:
- 凌晨4点,告警炸了
- 客户投诉涌进来
- 你盯着OpenAI状态页面干着急
- 老板问你怎么回事,你说”OpenAI挂了,我也没办法”
- 老板:“那为啥不搞个备用的?”
- 你:”…” 没有容错机制就是这么被动。主模型一挂,业务跟着挂,完全没有Plan B。你说慌不慌? 其实,如果有个AI Gateway配置好自动故障转移(Fallback),OpenAI挂了自动切换到Claude,Claude也挂了再切Gemini,整个过程秒级完成,用户甚至感觉不到。可用性直接从95%干到99.9%以上。
AI Gateway核心功能全解析
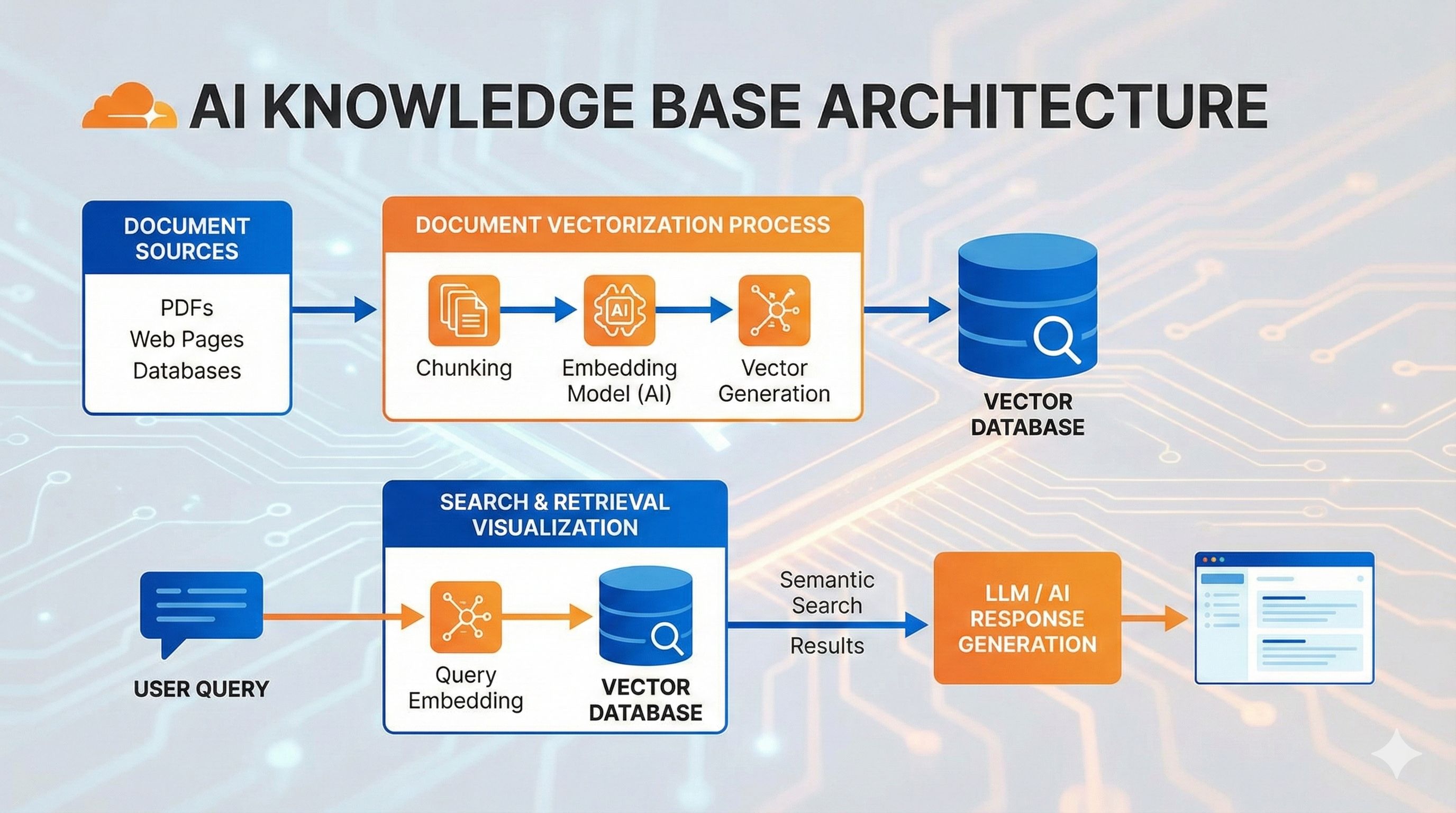
说了这么多痛点,那AI Gateway到底是咋解决的?其实它就像一个超级中间层,站在你的应用和各个AI服务商之间,帮你搞定所有脏活累活。
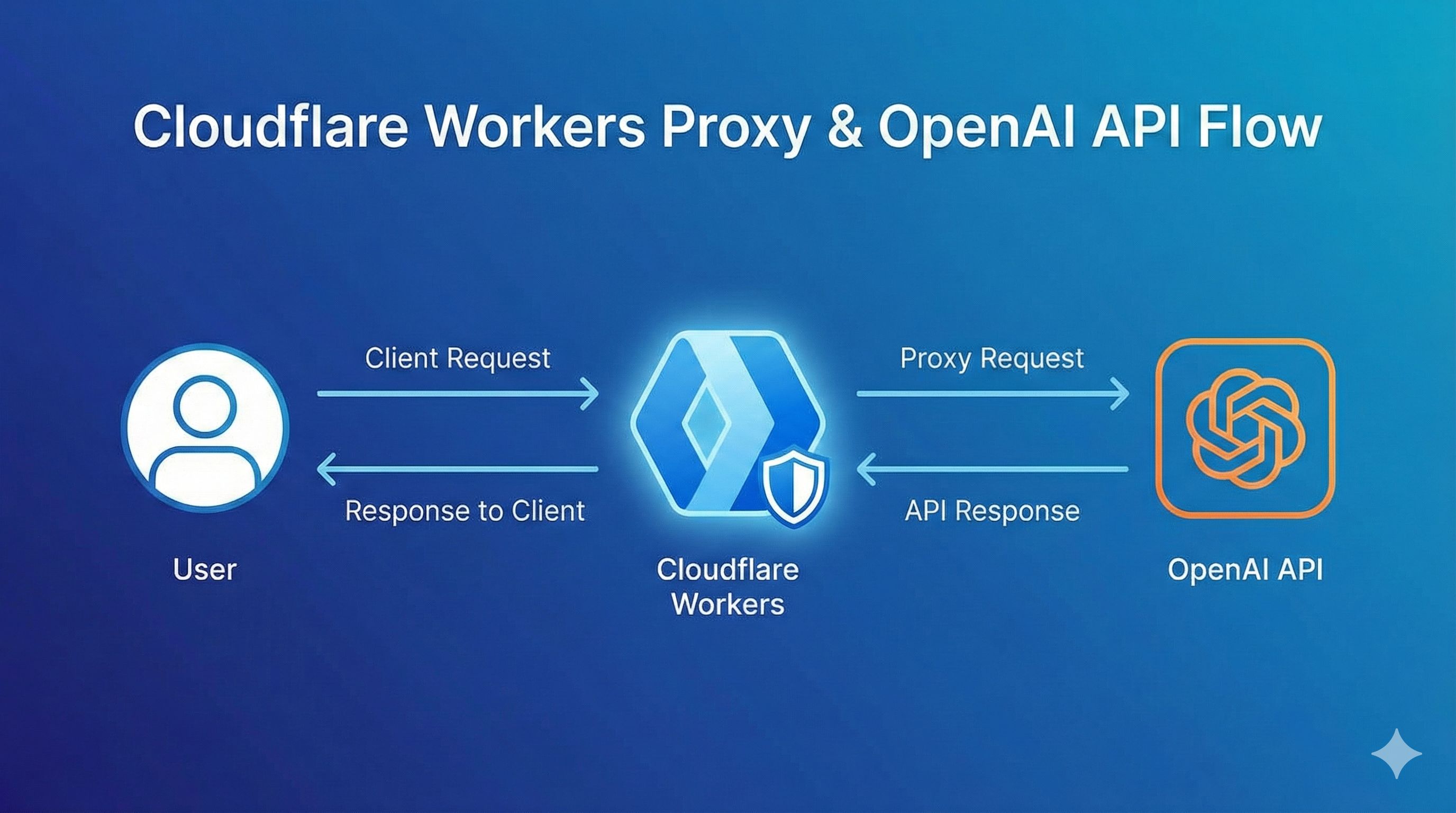
功能1:统一API入口 - 一套代码走天下
这个功能简直太爽了。你还是用熟悉的OpenAI SDK写代码,但只需要改一行baseURL,就能调用Claude、Gemini、甚至200+种模型。 比如用Portkey Gateway,你的代码是这样:
const openai = new OpenAI({
apiKey: 'your-openai-key',
baseURL: "http://localhost:8787/v1", // 就改这一行!
defaultHeaders: {
'x-portkey-provider': 'openai' // 想切Claude?改成'anthropic'就行
}
});
// 后面代码一行不改
const response = await openai.chat.completions.create({
model: "gpt-4",
messages: [{role: "user", content: "Hello"}]
});想切换到Claude?把x-portkey-provider改成anthropic,model改成claude-3-5-sonnet-20241022,完事!不用改任何业务逻辑,是不是超简单? Cloudflare的方案也类似,只需要把baseURL指向他们的Gateway endpoint就行。这样一来,你随时可以在OpenAI、Anthropic、Google、Azure之间切换,再也不用改一堆代码了。
功能2:智能缓存省钱 - 重复问题不花钱
这个功能是真省钱。原理很简单:AI Gateway会记住之前问过的问题和答案,如果有人又问了一遍,直接返回缓存结果,不调用API,不花token。 AI Gateway支持两种缓存:
- 精确缓存:问题文本完全一样才命中。比如你问了”什么是AI?“,下次再问这6个字,直接返回缓存
- 语义缓存:意思差不多就行。“什么是AI?”和”AI是什么?”是同一个意思,也能命中缓存 阿里云的数据显示,通义千问的缓存命中价格只有原价的40%。如果你的缓存命中率能做到50%,成本直接砍一半! 实际场景超级有用。比如客服机器人,用户经常问”怎么退货?""运费多少?“,这些高频问题开启缓存后,成本能降60%以上。 不过要注意,实时性要求高的别用缓存。比如”今天天气怎么样?""最新新闻是啥?“,这种问题缓存了就不对了。AI Gateway一般允许你配置缓存规则,哪些路径开缓存,缓存多久(TTL),都能自己定。
功能3:自动故障转移(Fallback) - 主模型挂了秒切备用
这个功能是稳定性保障。你可以配置多级Fallback策略,比如:
- 先调OpenAI GPT-4,重试5次
- 如果还失败,自动切换到Claude 3.5 Sonnet
- Claude也挂了,最后用Gemini Pro兜底 整个过程自动化,你的业务代码完全无感知。看个Portkey的配置示例:
{
"retry": { "count": 5 },
"strategy": { "mode": "fallback" },
"targets": [
{
"provider": "openai",
"api_key": "sk-xxx",
"override_params": {"model": "gpt-4"}
},
{
"provider": "anthropic",
"api_key": "sk-ant-xxx",
"override_params": {"model": "claude-3-5-sonnet-20241022"}
},
{
"provider": "google",
"api_key": "gt5xxx",
"override_params": {"model": "gemini-pro"}
}
]
}只要在header里传这个配置,Gateway就会按照你设定的顺序自动Fallback。Cloudflare的Universal Endpoint也支持类似功能,一个请求里填多个provider,自动切换。 有了这个,可用性能从95%提升到99.9%以上。OpenAI宕机?不怕,自动切Claude。Claude限流?没事,Gemini顶上。用户根本察觉不到,稳得一批。
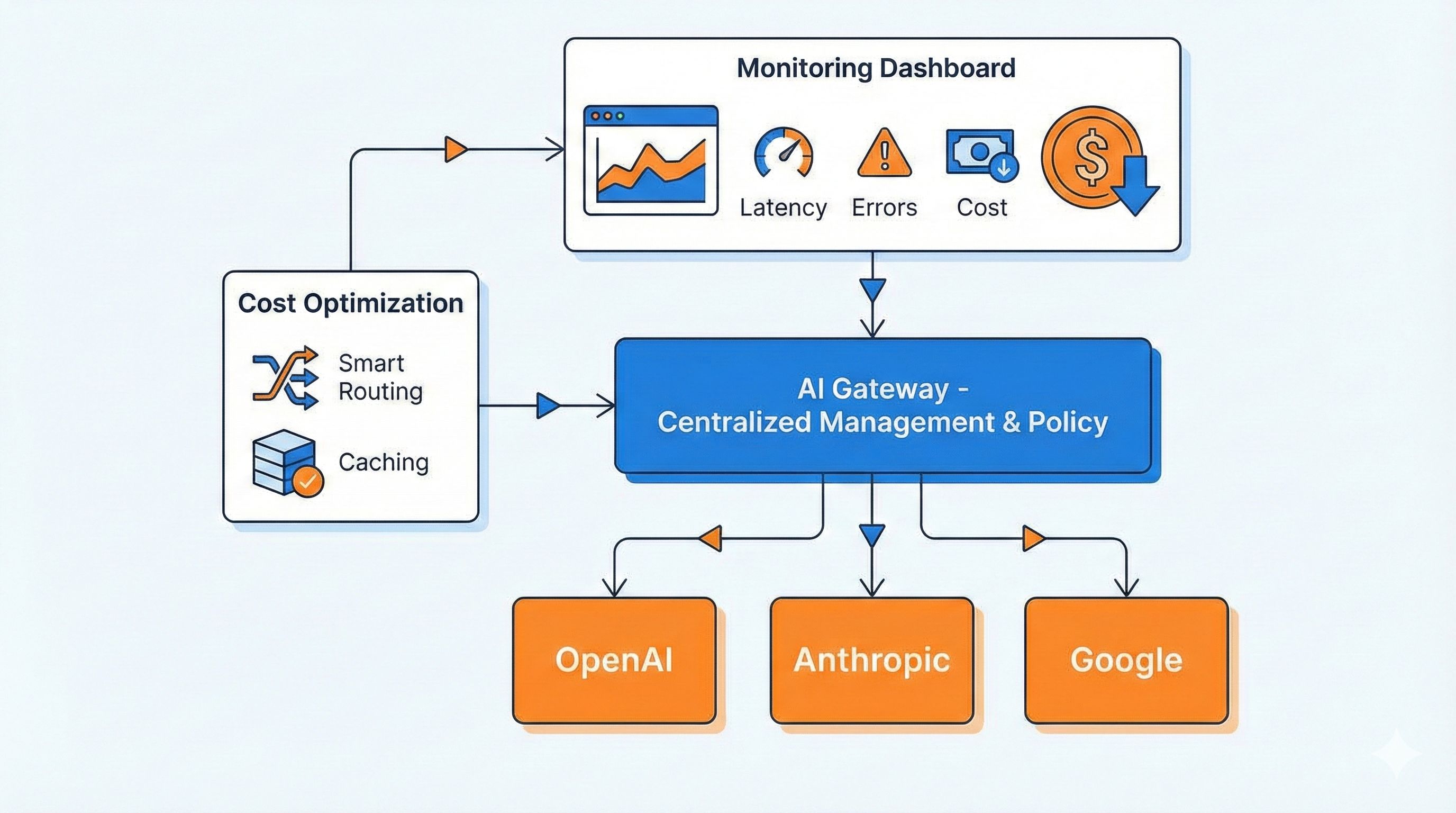
功能4:请求监控和成本分析 - 花钱心里有数
AI Gateway会实时记录每个请求的关键指标:
- QPS:每秒请求数,流量高峰一目了然
- Token消耗:每个模型用了多少token,实时统计
- 成本:按不同模型的定价算出实际花费
- 错误率:哪些请求失败了,什么原因 Cloudflare的监控面板特别强,除了基础的QPS和Error Rate,还有专门针对LLM的Token、Cost和Cache命中率面板。你能看到:
- 今天花了多少钱,趋势是涨是跌
- 哪个团队(消费者)用得最多
- 哪个模型最贵
- 缓存帮你省了多少钱 这下心里有数了吧?成本失控的问题彻底解决。你还能设置告警,比如”日消耗超100美元就通知我”,预算超了第一时间知道。
功能5:限流和权限管理 - 不让某个团队搞崩服务
企业级场景必备功能。你可以给不同团队分配独立的API Key,每个Key有自己的配额和限流规则。 比如:
- 研发团队:每天10万token额度,用GPT-4
- 测试团队:每天1万token额度,只能用GPT-3.5
- 产品团队:每天5万token额度,用Claude 这样一来,测试团队疯狂调用也不会把额度耗光,影响生产环境。每个团队用了多少,一清二楚。 高级一点的AI Gateway还支持敏感内容过滤,自动检测和拦截违规请求,保护数据安全。阿里云Higress就有这个能力,企业级安全管控都能搞定。
三大主流方案对比:Cloudflare vs Portkey vs 阿里云
市面上AI Gateway方案挺多,但主流的就这三家。咱们客观对比一下,帮你选出最适合的。
方案1:Cloudflare AI Gateway - 新手友好,上手最快
优势:
- 完全免费:所有Cloudflare账号都能用,不额外收费
- 零部署:不用装任何东西,注册账号就能用
- 一行代码接入:改个baseURL就行,5分钟搞定
- 全球加速:靠Cloudflare的CDN网络,速度快 限制:
- 数据会经过Cloudflare的服务器(虽然他们承诺不看)
- 语义缓存还在计划中,目前只有精确缓存
- 支持的模型相对少,10+主流提供商 适合场景:
- 个人项目,快速验证想法
- 小团队,没有运维资源
- 对数据隐私要求不那么严格的场景 Cloudflare的数据很牛,自2023年9月beta版发布以来,已经代理了超过5亿个请求。证明确实好用,大家都在用。
方案2:Portkey Gateway - 企业首选,功能最强
优势:
- 开源免费:GitHub上开源,私有部署完全可控
- 支持超多模型:200+ LLM,基本你能想到的都支持
- 性能爆表:官方数据比其他网关快9.9倍,安装后仅45kb
- 功能最全:负载均衡、自动重试、指数退避、50+护栏规则全都有 部署方式:
# 本地运行超简单
npx @portkey-ai/gateway
# 你的AI Gateway现在运行在 http://localhost:8787特色功能:
- 支持语义缓存(DashVector向量缓存)
- 自动重试机制特别智能,结合指数退避策略
- 可以部署到Cloudflare Workers、Docker、Node.js、Replit等多种环境 适合场景:
- 中大型企业,有数据安全合规要求
- 需要私有化部署
- 想要最强大的功能和最高的性能
方案3:阿里云Higress - 国内企业最佳
优势:
- 国内访问快:服务器在国内,延迟低
- 深度集成:无缝对接阿里云百炼、PAI平台
- 企业级稳定:阿里内部在用,支撑他们自己的AI应用
- MCP协议支持:支持API快速转MCP,适配最新标准 技术亮点:
- 三合一架构:容器网关 + 微服务网关 + AI网关
- 支持多云和私有化部署
- 专门针对国内大模型优化(通义、文心一言等) 适合场景:
- 已经在用阿里云的企业
- 需要混合云架构(本地+云端)
- 主要面向国内用户,延迟敏感
三大方案对比表
| 功能 | Cloudflare | Portkey | Higress |
|---|---|---|---|
| 部署方式 | 云服务 | 开源/云服务 | 私有化/云 |
| 价格 | 免费 | 开源免费 | 按量付费 |
| 支持模型数 | 10+ | 200+ | 主流全覆盖 |
| 语义缓存 | 计划中 | ✅ 支持 | ✅ 支持 |
| 私有部署 | ❌ | ✅ | ✅ |
| 国内访问 | 一般 | 一般 | ⭐⭐⭐ |
| 监控面板 | ⭐⭐⭐ | ⭐⭐ | ⭐⭐⭐ |
| 上手难度 | 超简单 | 简单 | 中等 |
| 企业级功能 | 基础 | ⭐⭐⭐ | ⭐⭐⭐ |
| 我的建议: |
- 个人项目/快速测试 → Cloudflare,5分钟上手,完全免费
- 创业公司/中小企业 → Portkey,开源免费,功能够用
- 大型企业/已用阿里云 → Higress,稳定可靠,服务有保障
- 海外项目 → Cloudflare或Portkey,别选国内的
- 国内项目且延迟敏感 → Higress,国内访问最快
实战演练:10分钟搭建你的第一个AI Gateway
光说不练假把式,咱们直接动手搞一个。我选Portkey做示范,因为它本地就能跑,不用注册账号,最快验证效果。
Step 1:一键部署Gateway(30秒)
打开终端,运行:
npx @portkey-ai/gateway看到这个提示就成功了:
🚀 AI Gateway running on http://localhost:8787就这么简单!你的AI Gateway已经在本地跑起来了。控制台访问 http://localhost:8787/public/ 还能看到管理界面。
Step 2:配置多模型Fallback(2分钟)
现在配置一个三级备份策略:OpenAI → Claude → Gemini。 创建一个配置文件 gateway-config.json:
{
"retry": {
"count": 5
},
"strategy": {
"mode": "fallback"
},
"targets": [
{
"provider": "openai",
"api_key": "你的OpenAI Key",
"override_params": {
"model": "gpt-4"
}
},
{
"provider": "anthropic",
"api_key": "你的Claude Key",
"override_params": {
"model": "claude-3-5-sonnet-20241022"
}
},
{
"provider": "google",
"api_key": "你的Google Key",
"override_params": {
"model": "gemini-pro"
}
}
]
}配置说明:
retry.count: 5→ 主模型失败时重试5次strategy.mode: "fallback"→ 使用故障转移模式targets→ 按顺序尝试三个提供商
Step 3:改造你的业务代码(1分钟)
原来你的代码可能是这样:
const openai = new OpenAI({
apiKey: 'sk-xxx'
});
const response = await openai.chat.completions.create({
model: "gpt-4",
messages: [{role: "user", content: "写一首诗"}]
});现在只需要改3行:
const fs = require('fs');
const config = JSON.parse(fs.readFileSync('./gateway-config.json'));
const openai = new OpenAI({
apiKey: 'any-key', // 不重要了,配置文件里有真实的key
baseURL: "http://localhost:8787/v1", // 👈 改这里
defaultHeaders: {
'x-portkey-config': JSON.stringify(config) // 👈 加这个
}
});
// 后面完全不用改!
const response = await openai.chat.completions.create({
model: "gpt-4", // 这个会被配置里的override_params覆盖
messages: [{role: "user", content: "写一首诗"}]
});就这样!现在你的代码已经有了三级容错能力。OpenAI挂了自动切Claude,完全无感知。
Step 4:测试Fallback效果(1分钟)
故意让OpenAI失败,验证是否自动切换。把配置文件里OpenAI的api_key改成错误的:
{
"provider": "openai",
"api_key": "sk-wrong-key", // 👈 故意写错
"override_params": {"model": "gpt-4"}
}运行代码,观察日志:
[Gateway] OpenAI request failed: Invalid API Key
[Gateway] Retrying with anthropic...
[Gateway] Success with anthropic (claude-3-5-sonnet-20241022)看到没?Gateway检测到OpenAI失败后,自动重试了5次,然后切换到Claude,最终成功返回结果。整个过程自动化,你的代码完全不需要处理错误。
Step 5:开启缓存降低成本(2分钟)
Portkey支持缓存,但需要配置。简化版可以用Redis:
// 如果你有Redis,可以这样配置缓存
const openai = new OpenAI({
baseURL: "http://localhost:8787/v1",
defaultHeaders: {
'x-portkey-config': JSON.stringify(config),
'x-portkey-cache': 'simple', // 开启简单缓存
'x-portkey-cache-force-refresh': 'false'
}
});第一次请求:
await openai.chat.completions.create({
messages: [{role: "user", content: "什么是AI?"}]
});
// 调用真实API,耗时800ms,花费0.002美元第二次相同请求:
await openai.chat.completions.create({
messages: [{role: "user", content: "什么是AI?"}]
});
// 命中缓存,耗时50ms,花费0美元看到效果了吧?速度快了16倍,成本直接省掉。高频问题越多,省得越多。
Step 6:查看监控数据(1分钟)
访问 http://localhost:8787/public/,你能看到:
- 总请求数和成功率
- 每个provider的调用次数
- 缓存命中率
- 错误日志 虽然Portkey本地版的监控面板比较简单,但够用了。如果你要更强大的监控,可以:
- 用Portkey Cloud(他们的托管版,免费额度够个人用)
- 换Cloudflare AI Gateway(监控面板超强)
- 自己对接Prometheus + Grafana
完整示例代码
把上面的整合起来,一个完整的例子:
const OpenAI = require('openai');
const fs = require('fs');
// 读取配置文件
const config = {
"retry": {"count": 5},
"strategy": {"mode": "fallback"},
"targets": [
{
"provider": "openai",
"api_key": process.env.OPENAI_KEY,
"override_params": {"model": "gpt-4"}
},
{
"provider": "anthropic",
"api_key": process.env.ANTHROPIC_KEY,
"override_params": {"model": "claude-3-5-sonnet-20241022"}
}
]
};
// 初始化客户端
const client = new OpenAI({
apiKey: 'placeholder',
baseURL: "http://localhost:8787/v1",
defaultHeaders: {
'x-portkey-config': JSON.stringify(config),
'x-portkey-cache': 'simple'
}
});
// 使用
async function chat(prompt) {
const response = await client.chat.completions.create({
model: "gpt-4", // 实际模型由配置决定
messages: [{role: "user", content: prompt}]
});
return response.choices[0].message.content;
}
// 测试
chat("用一句话解释AI Gateway").then(console.log);运行后,你会发现即使OpenAI失败,也能从Claude拿到回复,完全不影响业务。 实测数据:
- 部署时间:30秒(一行命令)
- 改造成本:改3行代码,5分钟搞定
- 成本降低:缓存命中率30%的情况下,成本降低约30%
- 可用性提升:从单模型95%提升到多模型99.5%以上
企业级最佳实践与避坑指南
搭建AI Gateway只是第一步,要真正用好它,还得注意这些细节。这些都是实际踩过的坑,血泪教训啊!
最佳实践1:分环境管理 - 开发生产别混用
这个坑我踩过。一开始图省事,开发测试生产都用一个Gateway配置,结果:
- 测试团队在生产环境疯狂调用,把配额耗光
- 开发调试时改了配置,生产也跟着变,直接炸了
- 账单分不清哪些是测试,哪些是真实业务 正确做法:
// 根据环境变量切换配置
const config = process.env.NODE_ENV === 'production'
? productionConfig // 生产:用GPT-4 + Claude 3.5备份
: developmentConfig; // 开发:用GPT-3.5省钱,甚至用本地模型
// 生产配置
const productionConfig = {
"targets": [
{"provider": "openai", "api_key": process.env.PROD_OPENAI_KEY,
"override_params": {"model": "gpt-4"}},
{"provider": "anthropic", "api_key": process.env.PROD_ANTHROPIC_KEY,
"override_params": {"model": "claude-3-5-sonnet-20241022"}}
]
};
// 开发配置
const developmentConfig = {
"targets": [
{"provider": "openai", "api_key": process.env.DEV_OPENAI_KEY,
"override_params": {"model": "gpt-3.5-turbo"}} // 便宜的模型
]
};这样开发测试想怎么玩怎么玩,不影响生产。API Key也分开,安全又省钱。
最佳实践2:成本控制策略 - 不让账单失控
没有成本控制就是烧钱。这几个策略必须上: 1. 为每个团队设置月度预算
// 在Gateway配置里设置限额
{
"consumer": "product-team",
"budget": {
"monthly_limit_usd": 1000, // 每月最多1000美元
"alert_threshold": 0.8 // 80%时告警
}
}2. 高频问题必须开缓存 统计你的请求,找出Top 10高频问题,全部开缓存。比如客服场景:
- “怎么退货?”
- “运费多少?”
- “发票怎么开?” 这些问题答案基本不变,缓存一周都没问题,能省60%以上的成本。 3. 定期审查Token消耗 每周看一次监控面板,找出Token消耗Top 10的请求:
- 有没有异常长的输入?(有人可能把整本书丢进去了)
- 哪些请求成本特别高?能不能优化prompt?
- 有没有重复请求?为啥没命中缓存? 我朋友公司发现有个请求每次都用8000 token,一查才知道prompt里包含了一堆不必要的例子。优化后降到2000 token,成本直接砍75%。
最佳实践3:安全防护 - 别让敏感数据泄露
这个特别重要,尤其企业场景。
1. 敏感数据不要发外部API 配置内容过滤器,自动检测手机号、身份证、信用卡等敏感信息:
// 伪代码,实际需要在Gateway层配置
if (request.content.contains(PHONE_PATTERN)) {
return error("检测到敏感信息,请求已拦截");
}Higress这类企业级网关都支持这个功能。
2. API Key定期轮换 不要一个Key用到天荒地老。每3个月轮换一次,泄露了也能及时止损。用Secret Manager管理,别硬编码在代码里。
3. 生产环境日志脱敏 Gateway的日志里别记录完整的用户输入,万一日志泄露就炸了:
// 日志示例(脱敏后)
{
"request_id": "abc123",
"model": "gpt-4",
"input_length": 256, // 只记录长度
"input_sample": "用户咨询关于...[已脱敏]", // 前10个字+脱敏
"cost": 0.002
}避坑指南1:缓存滥用 - 实时数据别缓存
踩坑案例:某天用户投诉”你们的天气预报怎么总是不准?”一查,原来AI返回的天气信息被缓存了24小时,用户早上问是晴天,晚上下雨了还说晴天。 解决方案: 区分场景,设置缓存白名单:
const cacheRules = {
// 可以缓存的路径
cacheable: [
"/api/ai/faq", // 常见问题
"/api/ai/docs-summary" // 文档总结
],
// 禁止缓存的路径
nocache: [
"/api/ai/realtime", // 实时数据
"/api/ai/news", // 新闻类
"/api/ai/personalized" // 个性化内容
]
};或者设置很短的TTL:
{
"cache": {
"ttl": 300 // 5分钟,适合准实时场景
}
}避坑指南2:Fallback配置不当 - 备用模型能力要匹配
踩坑案例:为了省钱,配置了GPT-4 fallback到GPT-3.5。结果GPT-4偶尔限流时,自动切到GPT-3.5,生成质量暴跌,用户直接投诉”你们的AI怎么突然变傻了?” 解决方案: 备用模型选同级别的,不要降级:
{
"targets": [
{"provider": "openai", "model": "gpt-4"},
{"provider": "anthropic", "model": "claude-3-5-sonnet"}, // ✅ 同级别
{"provider": "google", "model": "gemini-pro"} // ✅ 同级别
]
}不要这样:
{
"targets": [
{"provider": "openai", "model": "gpt-4"},
{"provider": "openai", "model": "gpt-3.5-turbo"} // ❌ 降级了
]
}如果实在要降级备用,至少做个提示:
if (response.provider === 'fallback_model') {
console.warn('当前使用备用模型,质量可能下降');
}避坑指南3:监控指标不看 - 部署了等于没部署
常见问题:很多团队辛辛苦苦部署了Gateway,结果从来不看监控面板,等出问题了才发现早就有征兆。 解决方案:
- 设置周报自动发送 每周一早上自动发邮件,包含:
- 上周总请求数、成功率、成本
- Token消耗Top 10
- 错误日志汇总
- 缓存命中率趋势
- 关键指标告警 必须配置的告警:
- 成本告警:日消耗超预算80%
- 错误率告警:失败率超5%
- 延迟告警:P99延迟超3秒
- Fallback告警:备用模型调用超20%
- 每周Review会议 技术负责人每周花15分钟看一次数据,问三个问题:
- 有没有异常的成本增长?
- 哪些错误可以优化?
- 缓存命中率还能提升吗? 真实案例:某公司每周Review后发现,周三下午3-5点请求量特别大。一查是产品团队每周三开会,会上疯狂测试新功能。调整后让他们用开发环境测试,生产环境成本直接降30%。
结论
说了这么多,其实核心就三句话:
第一,多AI服务商切换、成本失控、单点故障,这三个痛点只要做AI应用就避不开。你可以选择每次半夜起来改代码,也可以选择一次性把AI Gateway搭起来,从此高枕无忧。
第二,AI Gateway不是什么高深技术,10分钟就能跑起来。Portkey一行命令,Cloudflare注册就能用,真没那么复杂。改3行代码,就能获得多模型Fallback、智能缓存、全局监控,成本降40%,可用性提升到99.9%,这买卖划算得不行。
第三,部署只是开始,真正的价值在于持续优化。每周看一次监控数据,调整缓存策略,优化Fallback配置,清理无效请求…这些小动作积累下来,半年能帮你省几千甚至上万美元。 现在就行动:
- 今天就试试:花10分钟跑一个Portkey本地实例,感受一下有多简单
- 小步快跑:先在一个小项目试点,成功了再推广到全公司
- 养成习惯:每周一看一次监控面板,每月Review一次成本数据
- 分享经验:评论区说说你用AI Gateway遇到的问题,咱们一起交流 别等了,多服务商切换的麻烦只会越来越多,成本只会越来越高。早一天部署AI Gateway,早一天省心省钱。试试吧,反正又不花钱,万一效果好呢?
参考资料:
发布于: 2025年12月1日 · 修改于: 2025年12月4日